


Inconsistent Joined Output Data as a Result of Inconsistent Input Schema
This example Pipeline demonstrates how the Join Snap generates inconsistent output joined data by providing inconsistent input schema in your inputs.
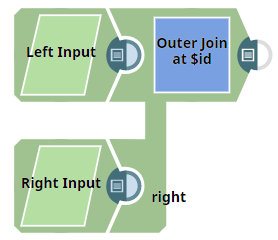
-
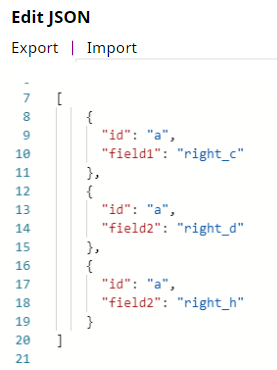
First, we provide input documents with inconsistent input schema using JSON Generator Snaps. The complete key set of input documents is
{“id”, “field1”, “field2”}. Note that field2 entry is missing in the first left input document, the field1 entry is missing in the second left input document, and so on. The missing entries with null values cause unexpected results in the joined output data.Left Input Schema Right Output Schema 
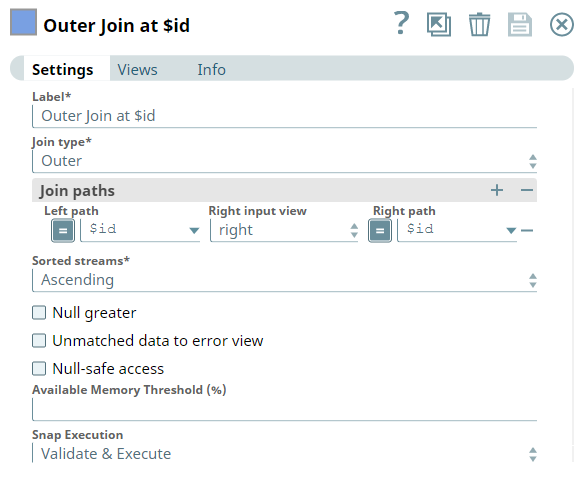
- Next, we connect the Join Snap to the upstream Snaps to join the left and right input
documents. To that end, we configure the Snap as shown below.
- Upon validation, the Snap displays inconsistent output result, because the input
documents contain incomplete key sets. The value right_c appears in the column
field1 and the values right_d and right_h appear in the column
field2
,wherein they should be under right_field1 and right_field2 columns respectively.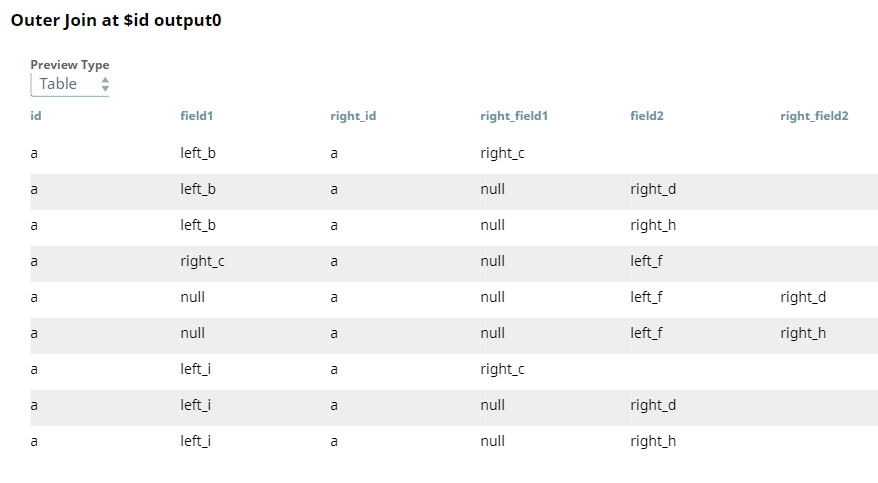
Note:
To reuse the example pipelines:
- Download and import the SLP file into your Environment.
- Configure Snap accounts.
- Provide Pipeline parameters, if any.