


Join
Overview
This Snap joins two or more data streams. It supports inner, left outer, and outer joins. If input data streams are sorted (ascending or descending), it is a streaming Snap at highly optimized performance. If the data streams are not sorted, you may use a Sort Snap in front of the Join Snap or select UNSORTED for the Sorted streams property. Please note that all documents in the same input view must have the same set of fields, otherwise, the naming of the fields in the output documents may appear to be inaccurate.
- This is a Transform-type Snap.
 Does not support Ultra Tasks
Does not support Ultra Tasks
Examples
Allowed: If one of the views on the Join Snaps is fed by an upstream FileReader.
Not Allowed: If you make a copy of the unlinked input stream and connect both of those output views to a Join Snap.
Prerequisites
All documents in the same stream should have the same set of fields.
Known issues
When the upstream Snaps of the Join Snap contains Copy, Router, Aggregate, or similar Snaps, it is likely that the data flow of a branch in a Pipeline gets blocked until another branch completes streaming the document. The Join Snap might hang if its upstream Snaps in a Pipeline has a blocked branch.
Workaround: Set Sorted streams to Unsorted in the Join Snap to effectively buffer all documents in all input views internally—this unblocks the document flow of all the upstream branches. The internal sorters sort the input documents from the input views into the local temporary stage.
Snap views
| Type | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input |
This Snap has two or more document input views. All documents in the same stream should have the same set of fields regardless if values are null or not. Important: The input data schema in the upstream Snaps of Join Snap must
be consistent for each input view to produce the expected joined output data.
Else, the Snap might output unexpected joined data.
See examples for more information. Workaround: You can insert a Mapper Snap to add missing fields with null values to fix the inconsistent input schema. |
|
| Output | This Snap has exactly one document output view. The output includes data joined from input document streams. Field names in the left input data are passed to the output data as is. For all field names in the right input document streams, if a field name conflicts with a field name in the left input data, it will be prefixed with its input view name. If there is no conflict, the field names in the right input documents are used in the output data without any modification. |
|
| Learn more about Error handling. | ||
Snap settings
- Expression icon (
 ): Allows using
pipeline parameters to set field values dynamically (if enabled). SnapLogic Expressions
are not supported. If disabled, you can provide a static value.
): Allows using
pipeline parameters to set field values dynamically (if enabled). SnapLogic Expressions
are not supported. If disabled, you can provide a static value. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values.
): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field/Field set | Type | Description |
|---|---|---|
Label
|
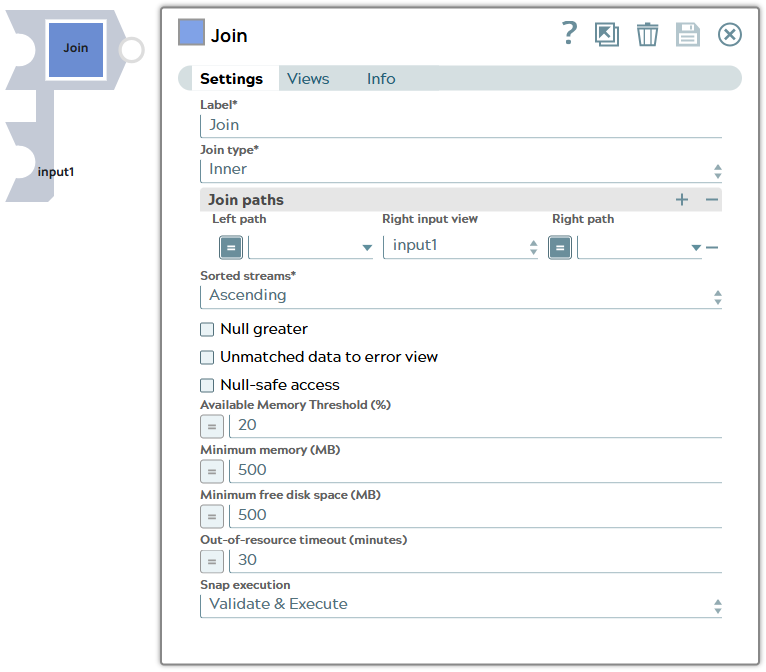
String | Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: Join Example: Join |
| Join Type | Dropdown list/Expression |
Required. The type of join to execute. The options
available include:
Important: If you select Merge, the documents from the
input views are merged into one document. You do not have to specify any other
join properties when merging documents. The rows on the left table are merged with the rows on the right table in the merge operation. If the right table has a fewer number of rows than the left table, null is added in the output document for the remaining rows. Default value: Inner Example: Outer |
| Join paths |
JSON paths to use for left and right sides of the join. Each row in the table defines a relationship between the left-field and one of the right fields. If there are N input views, N-1 rows are required to define each join path relationship. So, M*(N-1) rows are required to define all the join path relationships if there are M relationships. For example, if there are 4 input views and 3 join paths, 9 rows ((4-1) x 3) are required to define all the join path relationships. To use a partial set of join path relationships, use multiple Join Snaps. |
|
| Left path | Dropdown list/Expression | The JSON path to a value in a document of the first input view. One of the suggested field names should be selected. This property does not support expressions. Default value: None Example: $customer_id |
| Right input view | Dropdown list/Expression | Right input view name which is the second or another next input view. You can use the dropdown list to select the right input view name. Default value: None Example: input1 |
| Right path | Dropdown list/Expression | The JSON path to a value in a document of the second or another next input view. One of the suggested field names should be selected. This property does not support expressions. Default value: None Example: $customer_id |
| Sorted streams | Dropdown list/Expression | Required. Choose an option to sort the data
Ascending,
Descending, or Unsorted. If an Unsorted data stream is selected, the
Snap sorts input data streams before it starts the join operation. Default value: Ascending Example: Descending |
| Null greater | Checkbox | If selected, null values are considered greater than non-null values. In
conjunction with Sort streams:
|
| Unmatched data to error view | Checkbox | If selected, unmatched left input documents are passed to the error view only
if the Join type is 'Inner'. Default status: Deselected (false) |
| Null-safe access | Checkbox | If selected, the Snap will ignore missing data when accessing the join path.
For example, a join path is '$id', but the 'id' key does not exist in the input
data. In this case, the Snap will assume its value is null and continue. If
unselected, the Snap will write an error to the error view for missing data and stop
the execution. Default status: Not selected (false) |
| Available Memory Threshold (%) | Integer/Expression | The Snap keeps all the Right input view documents with the same join-path
values in memory until the join operation is done for the specific join-path values.
When the Right input view has more than 10,000 input documents with the same
join-path values, the Snap checks if the available memory is less than the threshold
value mentioned in this property. If so, it starts to store input data into local
temporary files to prevent the node from out of memory. Important:
|
| Minimum memory (MB) | Integer/Expression | If the available memory is less than this property value while processing input
documents, the Snap stops to fetch the next input document until more memory is
available. This feature is disabled if this property value is 0. Default value: 500 Example: 750 |
| Minimum free disk space (MB) | Integer/Expression | If the free disk space is less than this property value, the Snap stops
processing input documents until more free disc space is available. This feature is
disabled if this property value is 0. Default value: 500 Example: 750 |
| Out-of-resource timeout (minutes) | Integer/Expression | If the Snap pauses longer than this property value while waiting for more
memory available, it throws an exception to prevent the system from running out of
memory or disk space. Default value: 30 Example: 20 |
| Snap execution
|
Dropdown list |
Choose one of the three modes in
which the Snap executes. Available options are:
Default value: Execute only Default value: Validate & Execute |
Temporary files
During execution, data processing on Snaplex nodes occurs principally in-memory as streaming and is unencrypted. When processing larger datasets that exceed the available compute memory, the Snap writes unencrypted pipeline data to local storage to optimize the performance. These temporary files are deleted when the pipeline execution completes. You can configure the temporary data's location in the Global properties table of the Snaplex node properties, which can also help avoid pipeline errors because of the unavailability of space. Learn more about Temporary Folder in Configuration Options.