


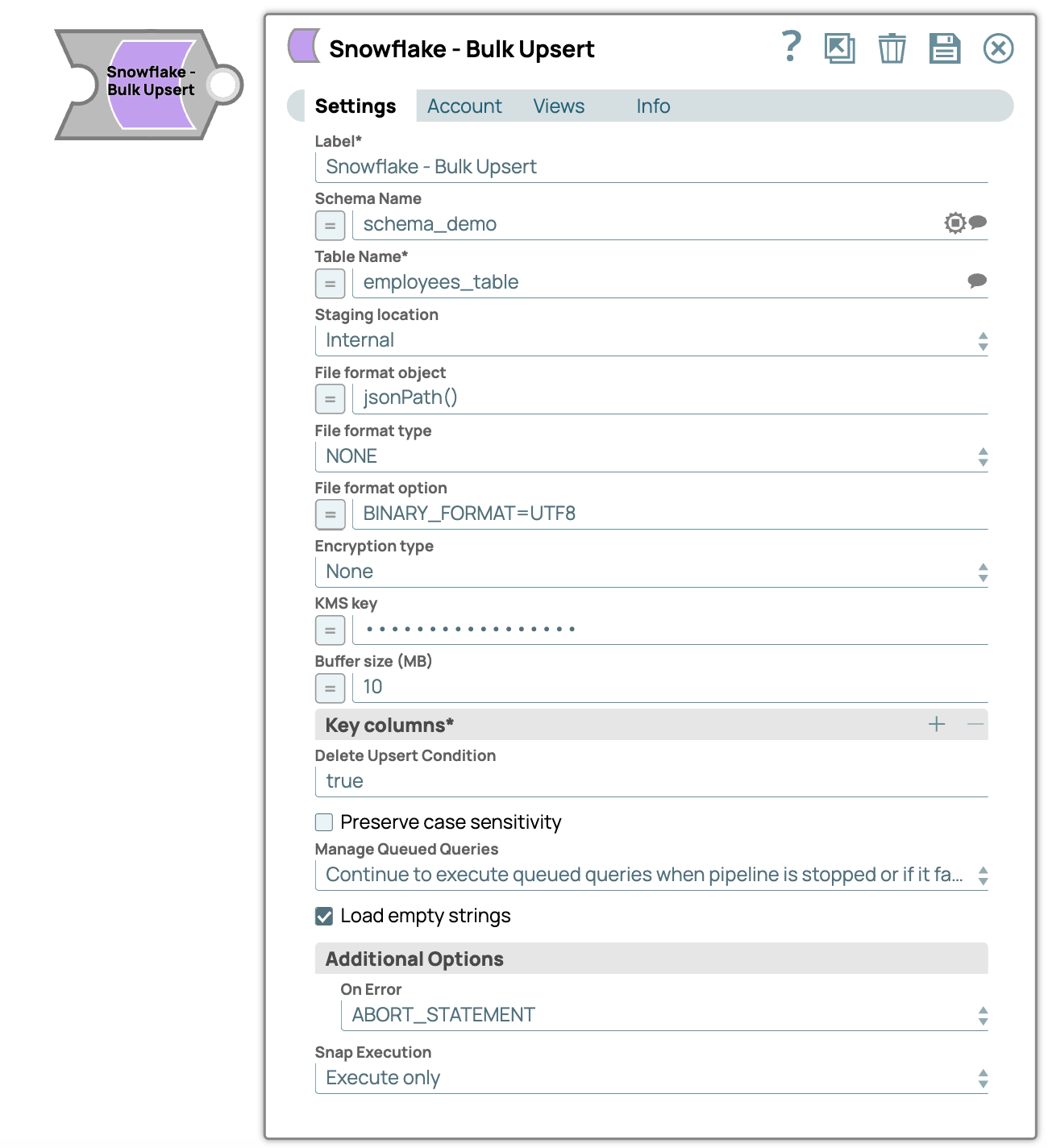
Snowflake - Bulk Upsert
Overview
- This is a Write-type Snap.
 Works in Ultra Tasks. However, we recommend that you do not use this Snap in an Ultra Pipeline.
Works in Ultra Tasks. However, we recommend that you do not use this Snap in an Ultra Pipeline.
Prerequisites
You must have minimum permissions on the database to execute Snowflake Snaps. To understand if you already have them, you must retrieve the current set of permissions. The following commands enable you to retrieve those permissions:
SHOW GRANTS ON DATABASE <database_name>
SHOW GRANTS ON SCHEMA <schema_name>
SHOW GRANTS TO USER <user_name>- Usage (DB and Schema): Privilege to use the database, role, and schema.
grant usage on database <database_name> to role <role_name>;
grant usage on schema <database_name>.<schema_name>;Learn more about Snowflake privileges: Access Control Privileges.
The below are mandatory when using an external staging location:
- The Snowflake account should contain S3 Access-key ID, S3 Secret key, S3 Bucket and S3 Folder.
- The Amazon S3 bucket where the Snowflake will write the output files must reside in the same region as your cluster.
- A working Snowflake Azure database account.
- SELECT FROM TABLE: SELECT as a statement enables you to query the database and retrieve a set of rows. SELECT as a clause enables you to define the set of columns returned by a query.
- COPY INTO <table>: Enables loading data from staged files to an existing table.
- CREATE TEMPORARY TABLE: Enables creating a temporary table in the database.
- MERGE: Enables inserting, updating, and deleting values in a table based on values in a second table or a subquery.
The following are mandatory when using an external staging location:
- Amazon S3 Bucket: The Snowflake account must include the S3 Access Key ID, S3 Secret Key, S3 Bucket Name, and S3 Folder Path.
- Amazon S3 Bucket: The S3 bucket must be located in the same region as your Snowflake cluster.
- Microsoft Azure Blob Storage: A valid and active Snowflake Azure database account is required.
- Google Cloud Storage: Ensure the storage bucket has the correct public access settings and access control permissions configured on the Google Cloud Platform.
Limitations and Known Issues
- The special character
~is not supported in the temporary directory name on Windows. It is reserved for the user's home directory. - Because of performance issues, all Snowflake Snaps now ignore the Cancel queued queries when pipeline is stopped or if it fails option for Manage Queued Queries, even when selected. Snaps behave as though the default Continue to execute queued queries when the Pipeline is stopped or if it fails option were selected.
Behavior change
In the 4.31 main18944 release and later, the Snowflake - Bulk Upsert Snap no longer supports values from an
upstream input document in the Key columns field when the expression button is
enabled. To avoid breaking your existing Pipelines that use a value from the input schema in
the Key columns field, update the Snap settings to use an input value from Pipeline
parameters instead.
Snap views
| Type | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | Incoming documents are first written to a staging file on Snowflake's internal staging area. A temporary table is created on Snowflake with the contents of the staging file. An update operation is then run to update existing records in the target table and/or an insert operation is run to insert new records into the target table. | |
| Output | If an output view is available, then the output document displays the number of input records and the status of the bulk upload. | |
| Learn more about Error handling. | ||
Snap settings
- Expression icon (
 ): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more.
): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values.
): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field/Field set | Type | Description |
|---|---|---|
| Label | String | Required.Specify a unique name for the Snap. Modify this to be more appropriate, especially if there are more than one of the same Snap in the pipeline. |
| Schema Name | String/Expression/ Suggestion | Required. Specify the database schema name. In case it
is not defined, then the suggestion for the Table Name retrieves all tables names of
all schemas. The property is suggestible and will retrieve available database
schemas during suggest values. Note: The values can be passed using the Pipeline
parameters but not the upstream parameter. Default value: N/A Example: Schema_demo |
| Table Name | String/Expression/ Suggestion | Required. Specify the name of the table to execute bulk
load operation on. Note: The values can be passed using the Pipeline parameters but
not the upstream parameter. Default value: N/A Example: employees_table |
| Staging location | Dropdown list/Expression | Select the type of staging location that is to be used for data loading:
Vector support:
Default value: Internal Example: External |
| Flush chunk size (in bytes) | String/Expression | Appears when you select Input view for Data source and Internal for Staging
location.When using internal staging, data from the input view is written to a
temporary chunk file on the local disk. When the size of a chunk file exceeds the
specified value, the current chunk file is copied to the Snowflake stage and then
deleted. A new chunk file simultaneously starts to store the subsequent chunk of
input data. The default size is 100,000,000 bytes (100 MB), which is used if this
value is left blank. Default value: N/A Example: 400000000 |
| File format object | String/Expression/ Suggestion | Specify an existing file format object to use for loading data into the table.
The specified file format object determines the format type such as CSV, JSON, XML,
AVRO, or other format options for data files. Default value: N/A Example: jsonPath() |
| File format type | String/Expression | Specify a predefined file format object to use for loading data into the table.
The available file formats include CSV, JSON, XML, and AVRO. Note: This Snap
supports only CSV and NONE as file format types when the
Datasource is Input view. Default value: N/A Example: CSV |
| File format option | String/Expression | Specify the file format option. Separate multiple options by using blank spaces
and commas. Note:
You can use various file format options including a binary format which passes
through in the same way as other file formats. Learn more: File Format Type Options. Before loading
binary data into Snowflake, you must specify the binary encoding format, so that
Snap can decode the string type to binary types before loading it into
Snowflake. This can be done by selecting the following binary file format:
Default value: N/A Example: BINARY_FORMAT=UTF8 |
| Encryption type | Dropdown list | Specify the type of encryption to be used on the data. The available encryption
options are:
The KMS Encryption option is available only for S3 Accounts (not for Azure Accounts) with Snowflake. Note: If Staging Location is set to Internal, and
when Data source is Input view, the Server Side Encryption and Server-Side KMS
Encryption options are not supported for Snowflake snaps: This happens because
Snowflake encrypts loading data in its internal staging area and does not allow
the user to specify the type of encryption in the PUT API. Learn more: Snowflake PUT Command
Documentation. Default value: None Example: Server-Side Encryption |
| KMS key | String/Expression | Specify the KMS key that you want to use for S3 encryption. Learn more about
the KMS key: AWS KMS Overview and Using Server Side Encryption. Note: This
property applies only when you select Server-Side KMS Encryption in the
Encryption Type field above. Default value: N/A Example: <Encrypted> |
| Buffer size (MB) | String/Expression | Specify the data in MB to be loaded into the S3 bucket at a time. This property
is required when bulk loading to Snowflake using AWS S3 as the external staging area.
Note: S3 allows a maximum of 10000 parts to be uploaded so this property must
be configured accordingly to optimize the bulk load. Refer to Upload Part for more
information on uploading to S3. Default value: 10MB Example: 20MB |
| Key columns | Specify the column to use for existing entries in the target table.
Note: The Key columns field does not support values from the upstream input document when the expression button is enabled. The value must be defined for all inputs and remain constant throughout the Snap execution. Therefore, the Snap supports expressions to include only constant pipeline parameters. If you are using a function to get or transform the value from a pipeline parameter, that value must evaluate to a value that is not null and is not empty at the time of pipeline execution.
|
|
| Delete Upsert Condition | String | Delete Upsert Condition when true, causes the case to be executed. Default value: N/A Example: True |
| Preserve case sensitivity | Checkbox | Select this checkbox to preserve the case sensitivity of the column names.
Default status: deselected |
| Manage Queued Queries | Dropdown list | Choose an option to determine whether the Snap should continue or cancel the
execution of the queued queries when the pipeline stops or fails. Note: If you
select Cancel queued queries when the Pipeline is stopped or if it fails,
then the read queries under execution are canceled, whereas the write type of
queries under execution are not canceled. Snowflake internally determines which
queries are safe to be canceled and cancels those queries. |
| Load empty strings | Checkbox | Select this checkbox to load empty string values in the input documents as
empty strings to the string-type fields. Else, empty string values in the input
documents are loaded as null. Null values are loaded as null regardless.
Default status: deselected |
| On Error | Dropdown list | Select an action to perform when errors are encountered in a file. The available actions are:
|
| Strings considered as null | String/Expression | Specify the strings to be considered as null when loading into Snowflake. You
can configure multiple case-sensitive comma-separated strings from the input data as
null placeholders. This ensures effective handling of null values without impacting
existing data and optimizes the storage space in the internal stage. Default value: N/A Example: ^_AB, _nullIf |
| Error Limit | Integer | Appears when you select SKIP_FILE_*error_limit* for
On Error. Specify the error limit to skip file. When the number of errors in
the file exceeds the specified error limit or when SKIP_FILE_number is selected for
On Error. Default value: 0 Example: 3 |
| Error Percentage Limit | Integer | Appears when you select
SKIP_FILE_*error_percent_limit*% for
On Error. Specify the error limit to skip file. When the
number of errors in the file exceeds the specified error limit or when
SKIP_FILE_number is selected for On Error. Default value: 0 Example: 1 |
| Snap execution
|
Dropdown list |
Choose one of the three modes in
which the Snap executes. Available options are:
Default value: Execute only Example: Validate & Execute |
Troubleshooting
Cannot lookup a property on a null value.
The value referenced in the Key Column field is null.
This Snap does not support values from an upstream input document in the Key columns field when the expression button is enabled.
Update the Snap settings to use an input value from pipeline parameters and run the pipeline again.
Data can only be read from Google Cloud Storage (GCS) with the supplied account credentials (not written to it).
Snowflake Google Storage Database accounts do not support external staging when the Data source is the Input view.
Data can only be read from GCS with the supplied account credentials (not written to it).
Use internal staging if the data source is the input view or change the data source to staged files for Google Storage external staging.