


Google VertexAI Embedder
Overview
Use this Snap to process the input and generate an embedding vector. The Snap generates the corresponding embedding for the output document, regardless of the batch size.
- This is a Transform-type Snap.
 Works in Ultra Tasks
Works in Ultra Tasks
Prerequisites
Supported models:
- text-embedding-005
- text-multilingual-embedding-002
- text-embedding-large-exp-03-07
You need to have one of the following accounts configured for your Google VertexAI Snaps:
Limitations and known issues
None.
Snap views
| Type | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | This Snap has at the most one document input view. The Snap requires the text to generate the embedding vector. | |
| Output | This Snap has at the most one document output view. The Snap provides the embedded vectors, and the original input document. | Mapper |
| Learn more about Error handling. | ||
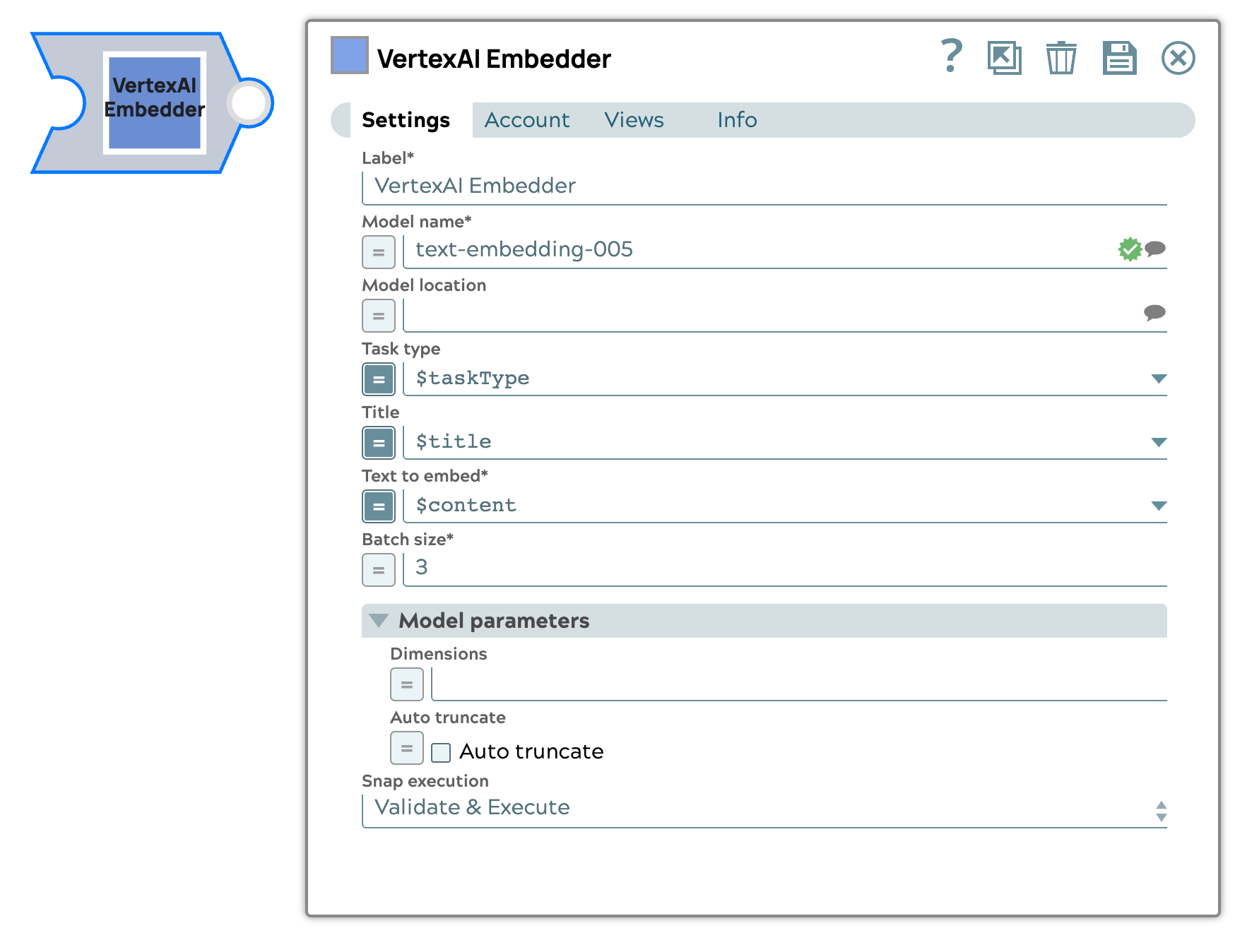
Snap settings
- Expression icon (
 ): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more.
): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values.
): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field/Field set | Type | Description |
|---|---|---|
Label
|
String |
Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: VertexAI Embedder Example: RAG index |
| Model name | String/Expression/ Suggestion |
Required. The identifier for the Google Gemini embedding model. Default value: N/A Example: text-embedding-005 |
| Model location | String/Expression/ Suggestion |
The location of the model. Default value: N/A Example: us-central1 |
| Task type | String/Expression/ Suggestion |
The task type for the embedding. Default value: RETRIEVAL_DOCUMENT Example:QUESTION_ANSWERING (Expression enabled) |
| Title | String/Expression |
The title of the document is used to improve the model's ability to generate better embeddings. This is relevant when working with RETRIEVAL_DOCUMENT tasks Default value: N/A Example: “doc1” |
| Text to embed | String/Expression |
Required. The text that you want to generate embeddings for. Default value: N/A Example: "content" |
| Batch size | Integer/Expression |
Required. The number of documents batched per request. If running in Ultra mode, this must be set to 1. Default value: 1 Example: 1 |
| Model parameters |
Parameters used to tune the model runtime. |
|
| Auto truncate | Checkbox/Expression |
If true, the text will be truncated to fit the model's maximum input length. Default status: Deselected |
| Dimensions | Integer/Expression |
Specify the output embedding size. If set, the output embeddings will be truncated to the specified size. Default value: N/A Example: 10 |
| Snap execution
|
Dropdown list |
Choose one of the three modes in
which the Snap executes. Available options are:
Default value: Validate & Execute Example: Execute only |