


FAQ: Snowflake Metadata Caching
What is Metadata Caching?
The metadata caching mechanism in Snowflake temporarily stores metadata in Snaplex (JCC Node) memory to improve performance and reduce the need for repeated retrieval or computation. This feature is designed to optimize performance and reduce redundant metadata queries, particularly for high-frequency and large-scale workloads. However, its use depends on the nature of your data and deployment model.
What are the benefits of Metadata Caching?
-
Consistency: Shared metadata across Snap phases.
-
Cost-effective: Reduces Snowflake query costs, especially related to repeated metadata lookups.
-
Efficiency: Reduces computation if metadata needs to be derived or parsed.
-
Performance: Faster Snap execution by eliminating redundant metadata fetches.
-
Scalability: Reduces load on back-end systems or services.
How does Metadata Cache work?
The cache on the Snaplex (JCC node) is empty initially. When the Snap executes, it looks for metadata (such as the list of tables and column names). Because the cache is empty, the Snap makes a JDBC call to retrieve this information from the server, and the data is then stored in the cache. As long as this data remains in the cache, the Snap reuses these entries to avoid additional calls to the database, which improves performance. After the expiration time for the cache entries elapses, these entries are removed. The same process is repeated for subsequent Snap executions.
When is the cache in sync with the database?
The cache remains in sync only if all operations pass through the cache-enabled Snaplex. Based on the Snap configuration, the cache module adds metadata information accordingly.
When is the cache out of sync with the database?
If metadata is modified (such as deleting existing tables and columns or adding new tables and columns) directly in the Snowflake server without going through the actual cache node, the cache goes out of sync.
What happens when the cache is out of sync?
The pipelines might fail because of metadata mismatch between the cache on the server and that on the node.
How to avoid a cache out of sync?
Configure the Expiration duration
(snapogic.db.metadata.cache.duration.minutes) and ensure that you do not
update the metadata on the Snowflake server within the expiration time.
How to configure metadata caching in Snaplex?
| Cache property | JVM Option |
|---|---|
| Cache status: Set this value to true to enable caching. | snapogic.db.metadata.cache.enabledDefault value: false Example: |
| Cache size: Maximum entries in cache mode. Entry refers to complete schema information. | snapogic.db.metadata.cache.sizeDefault value: 1000 Example:
|
| Cache expiration duration: Expiration duration (minutes). | snapogic.db.metadata.cache.duration.minutesDefault value: 120 Example: Note:
We recommend a short expiration time if schema changes happen
occasionally. |
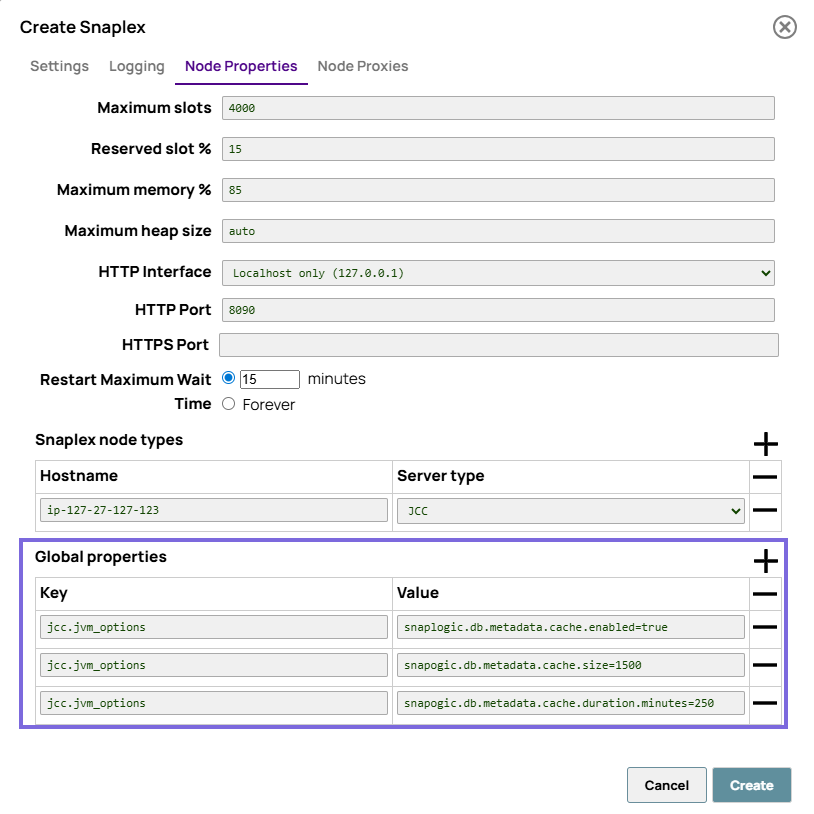
When should you enable metadata caching?
You must enable metadata caching in the following cases:
-
If the schema is relatively static (when the table structure doesn't change frequently).
-
For high-volume pipelines or frequent Snap executions where repeated metadata lookups add overhead.
-
For data pipelines that are stable and mature, with a low risk of schema evolution.
When should you disable metadata caching?
You must disable metadata caching in the following cases:
-
If Snowflake tables undergo frequent schema changes (for example, column additions, type changes, and table recreations).
-
If there is a multi-node Snaplex where schema changes are made directly in Snowflake (outside SnapLogic), leading to inconsistent cache across nodes.
-
If you require immediate visibility into metadata updates (for example, during testing or development).
-
When you rely on dynamic or programmatically generated schemas as part of your pipelines.
Best Practices
-
Use a short cache expiration time (
cache.duration.minutes) in environments with occasional schema updates, but still want the performance benefit of caching. -
Implement a governed schema change process so any updates made in Snowflake are propagated consistently across nodes (for example, using pipeline-triggered table updates).
-
Monitor for schema mismatch or metadata errors in logs to quickly catch stale cache issues.
Cache sync behavior scenarios
| Scenario | Cache Sync Status | Risk |
|---|---|---|
| When the table metadata is modified via SnapLogic on one node. | The node has updated data. | ⚠️ Other nodes might be stale. Some users might see outdated data. |
| When table metadata is modified directly in Snowflake. | The cache is not refreshed anywhere. | ❗High. All users might see old data. |
| When the table is dropped and created again via SnapLogic on the same node. | The cache is synced, and the node is up-to-date. | ⚠️ Other users might still use the old version. |
| When the cache TTL (Time to live) expires. | The cache is refreshed, and all caches eventually get updated. | 🕒 There will be a delay until refresh. |