


Historize incoming records
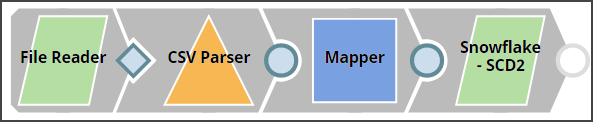
This example pipeline demonstrates how to auto-historize incoming records using the Snowflake SCD2 Snap. The pipeline reads, parses, maps, historizes, and then upserts data into the Snowflake target table.
-
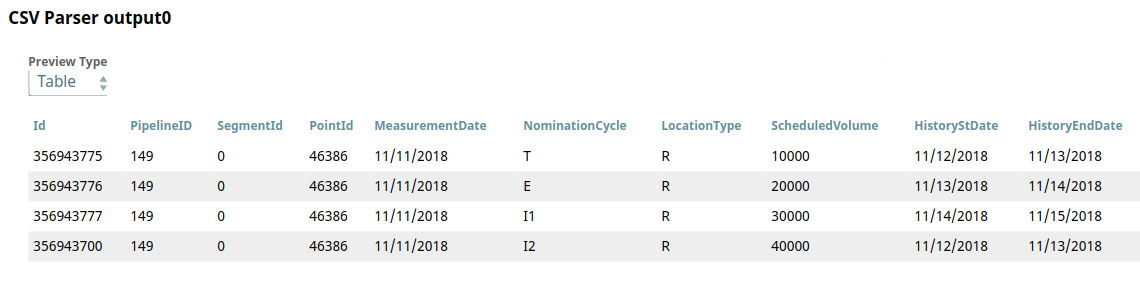
Understand the target table structure with historization-specific
columns.

- POINT ID: The natural key used to identify records.
- SCHEDULEDVOLUME: The field on which historization is triggered when its value changes.
- HISTORYSTARTDATE and HISTORYENDDATE: Used to identify the current record.
- FLAG: Indicates whether the record is current (
TRUE) or historical (FALSE). - STARTDATE and ENDDATE: Automatically populated by the Snap. The ENDDATE is blank for the current record.
-
Configure the File Reader and CSV Parser Snaps to load and parse the incoming data.
The File Reader Snap reads a CSV file containing the incoming records. The CSV Parser Snap parses this file for further transformation.
-
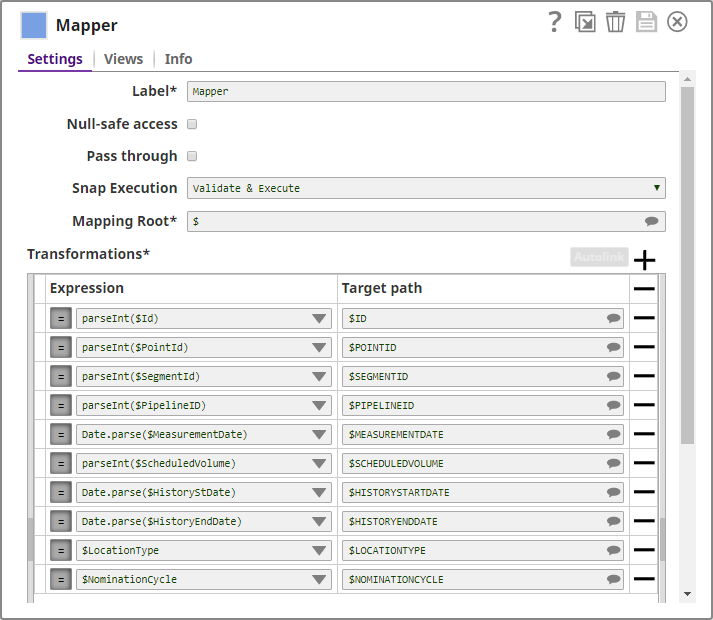
Use the Mapper Snap to map and convert field types.
Because the CSV Parser Snap outputs strings, the Mapper Snap is used to parse fields into appropriate data types and prepare data for historization.
-
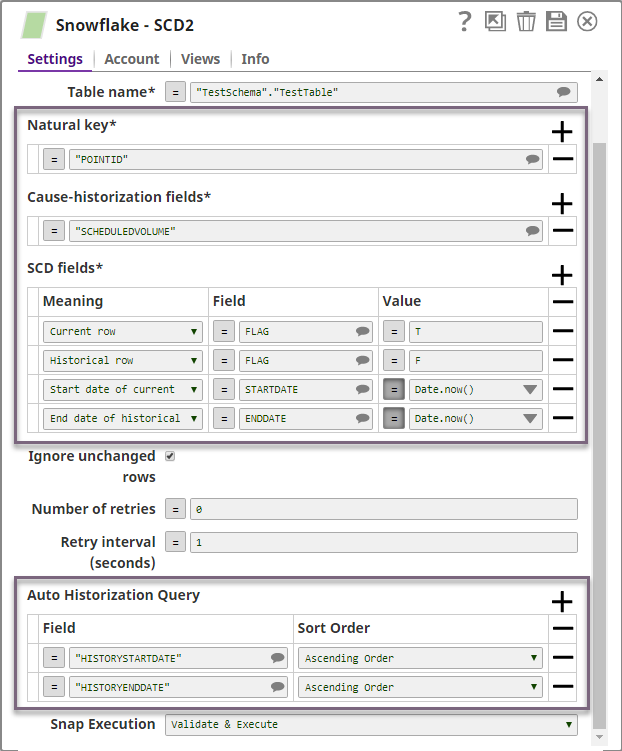
Configure the Snowflake SCD2 Snap with historization logic.
- Natural key: Set to
POINT ID, allowing the Snap to group and track changes by key. - Cause-historization fields: Specify
SCHEDULEDVOLUMEto trigger historization on value change. - FLAG field: Indicates current (
T) or historical (F) records. - Auto historization logic: The Snap identifies the current record using
HISTORYSTARTDATEandHISTORYENDDATEand historizes all newer records. - STARTDATE/ENDDATE: Automatically set using
Date.now(). The current record will always have a blank ENDDATE.
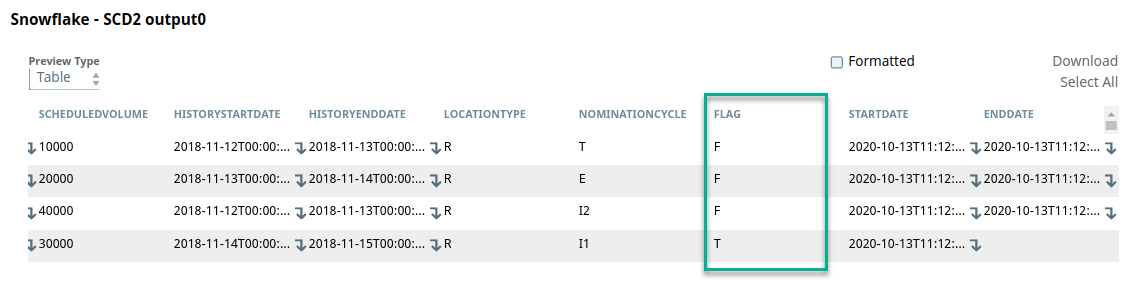
The Snap historizes incoming records by assigning FLAG =Fand evaluating STARTDATE/ENDDATE. The updated output is passed downstream. - Natural key: Set to
-
Use the Snowflake - Bulk Upsert Snap to upsert the historized data into the target table.
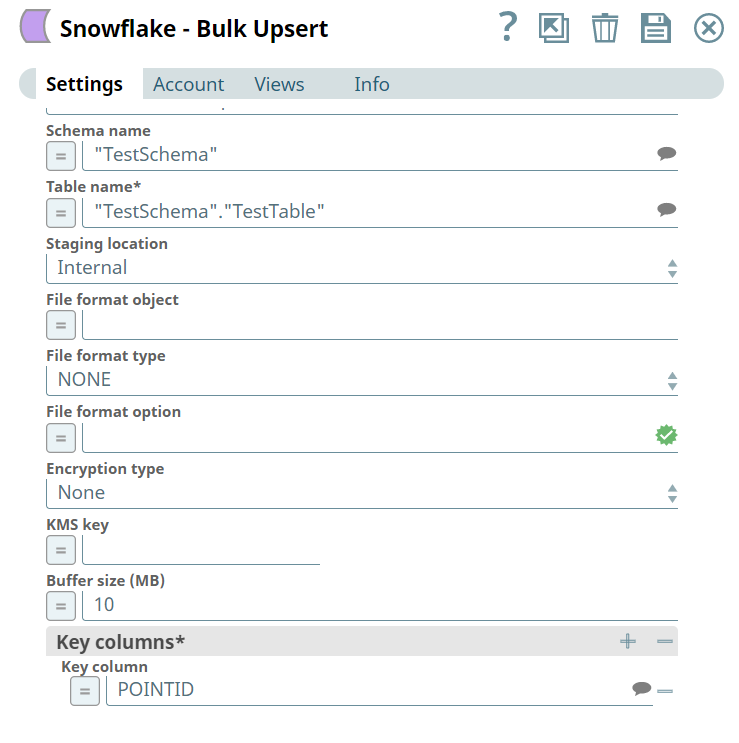
The Snap inserts the latest and historized records into the Snowflake table as per SCD2 rules.