Use Case: Move Data Using Snowflake Snap Pack
Overview
This use case demonstrates a practical application of the Snowflake Snap Pack to automate and optimize the movement of data from a PostgreSQL database to a Snowflake environment.
Problem
Manually transferring data from PostgreSQL to Snowflake can be time-consuming and
error-prone, particularly with large datasets. Manual data transfers require:
- Correct mapping of datatypes between PostgreSQL and Snowflake.
- Schema adjustments or transformations during transfer.
- Monitoring and performance optimization.
- Setting up scheduling mechanisms for recurring data movement.
Solution
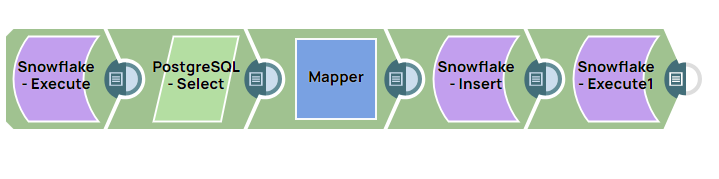
This pipeline addresses the above challenges by automating the process. It truncates the existing Snowflake table, extracts data from a PostgreSQL source, maps the data into variables, and inserts it into a Snowflake table, followed by data validation.
Understanding the Solution
- Automation: Replace manual transfers with an automated pipeline to reduce errors and save time.
- Data Integrity: Validate data transfer by retrieving and displaying Snowflake table content post-insertion.
- Performance: Improve performance by staging, truncating, and cleanly inserting data in batch.
- Reusability: Use pipeline variables to easily configure and reuse the solution for different tables.
-
Use the Snowflake - Execute Snap to execute a
TRUNCATE TABLESQL query in Snowflake. This ensures the target table is cleared before data insertion.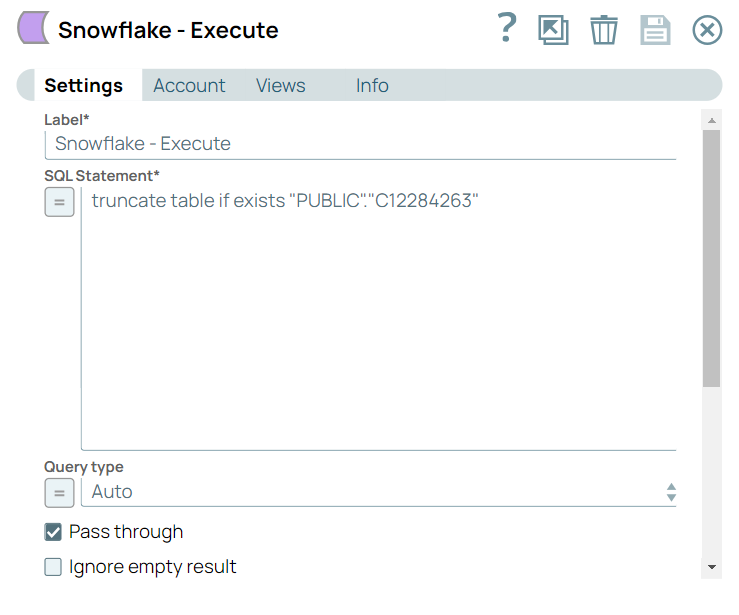
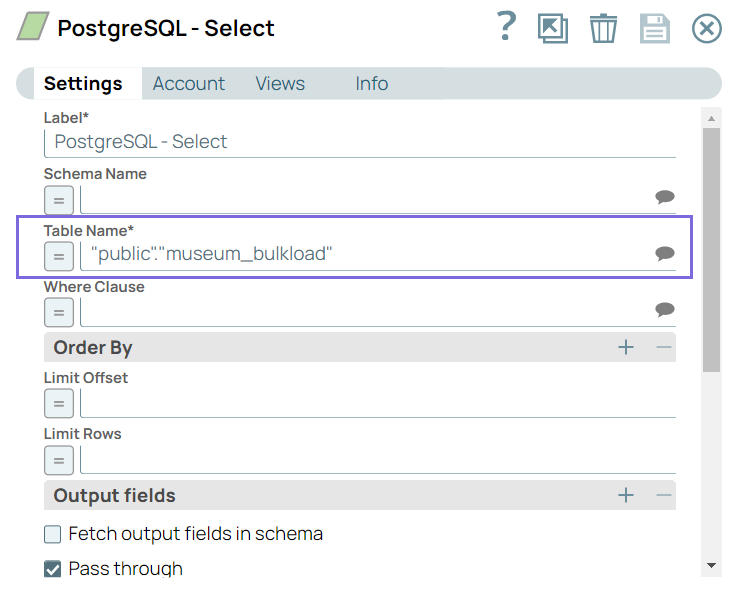
- Configure the PostgreSQL Select Snap to extract the required
table data from the PostgreSQL database that you want to transfer to
Snowflake.
-
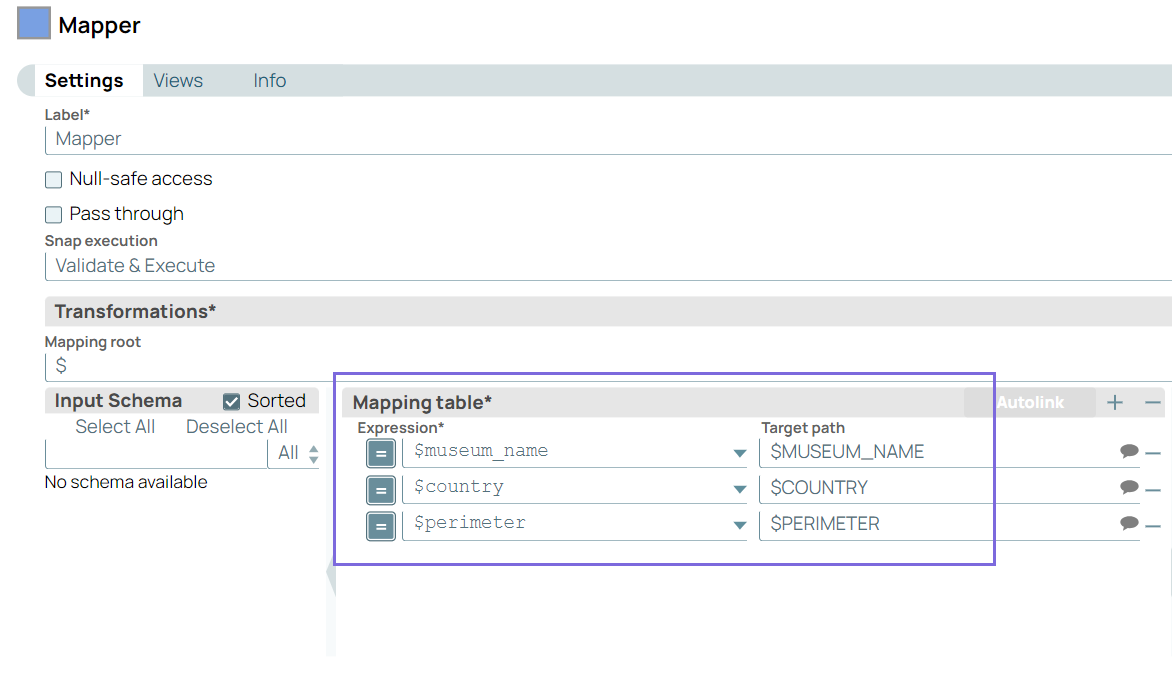
Use the Mapper Snap to map source
columns to pipeline variables or transform the structure for insertion into
Snowflake.
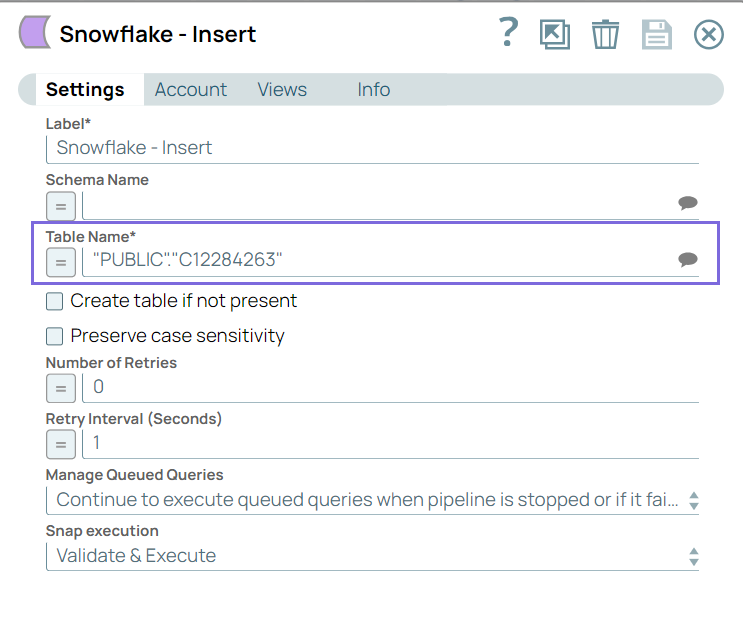
- Configure the Snowflake - Insert Snap to insert the extracted
data from PostgreSQL into the Snowflake database in the C12284263 table.
-
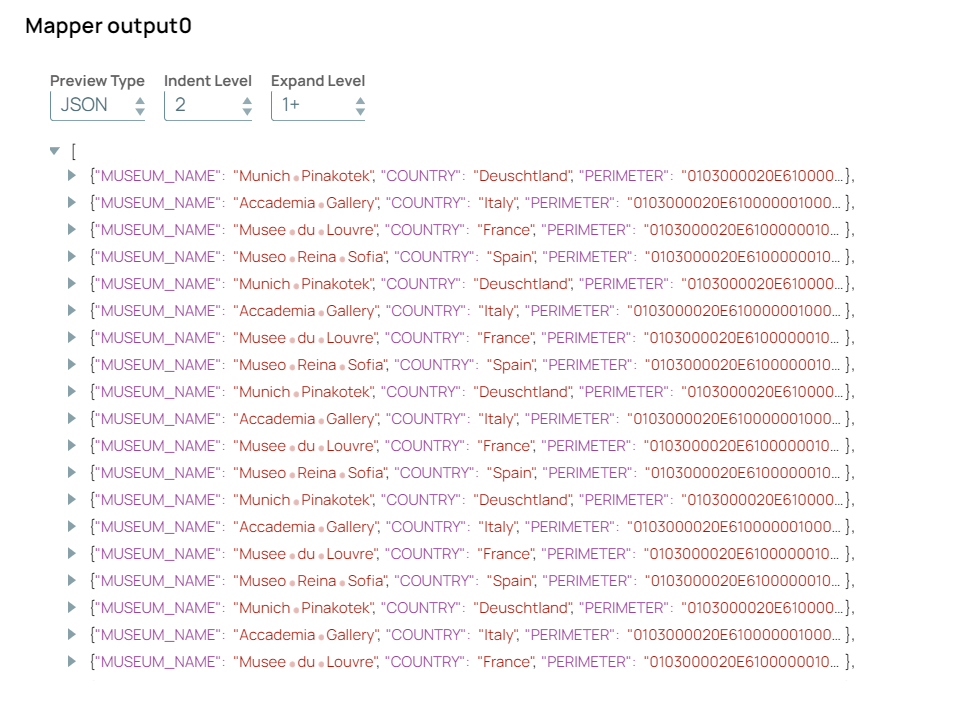
Use another instance of the Snowflake - Execute
Snap to retrieve and preview data from the Snowflake table, ensuring that the
expected records were inserted correctly.