


Predictor (Classification)
enables you to predict the class (target/class) field for an unlabeled document.
Overview
 Transform-type Snap
Transform-type Snap-
 Works in Ultra Pipelines
Works in Ultra Pipelines
Predictor (Classification) enables you to predict the class (target/class) field for an unlabeled document.
For this Snap, an unlabeled document is defined as one that does not have a class field. So, the Snap reads this unlabeled document and predicts the class field. Predictions are made based on the classification model built by the Trainer (Classification) Snap.
You can configure the Snap to include the confidence level for the prediction. You can additionally specify if the Snap shows multiple predictions for a given input.
Prerequisites
- The data from upstream Snap must be in tabular format (no nested structure).
Limitations and known issues
None.
Snap views
| View | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input #1 | An unlabeled document that requires prediction(s). | Any Snap that generates an unlabeled document. Examples: |
| Input #2 | The classification model. | Any Snap that reads and outputs the classification model. Examples: A combination of File Reader and JSON Parser |
| Output | Predictions from the classification model based on the input document. Multiple predictions are displayed depending upon the configuration of the Max output property. Additionally, the confidence level for each prediction is displayed if the Confidence level property is selected. | Any Snap that uses the predicted result.
Examples:
|
| Error |
Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter when running the pipeline by choosing one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. |
|
Snap settings
-
Suggestion icon (
 ):
Indicates a list that is dynamically populated based on the configuration.
):
Indicates a list that is dynamically populated based on the configuration.
-
Expression icon (
 ):
Indicates whether the value is an expression (if enabled) or a static value (if disabled).
Learn more about Using Expressions in SnapLogic.
):
Indicates whether the value is an expression (if enabled) or a static value (if disabled).
Learn more about Using Expressions in SnapLogic.
-
Add icon (
 ):
Indicates that you can add fields in the field set.
):
Indicates that you can add fields in the field set.
-
Remove icon (
 ):
Indicates that you can remove fields from the field set.
):
Indicates that you can remove fields from the field set.
| Field / Field set | Type | Description |
|---|---|---|
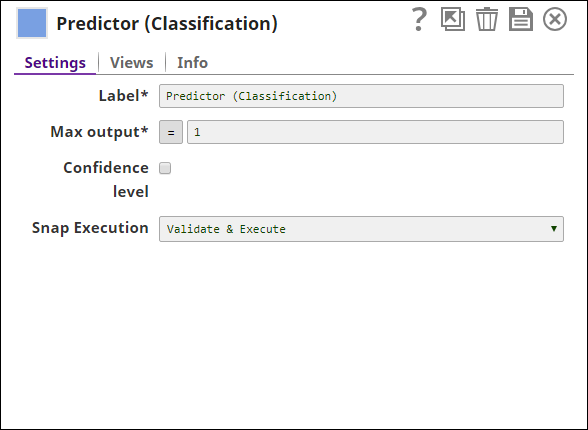
| Label | String | Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if there are more than one of the same Snap in the pipeline. |
| Max output | integer | Required. The maximum number of predictions for each row in the input document.
The predictions are in descending order of their confidence level.
Valid values: 1 through the largest integer Default value: 1 |
| Confidence level | checkbox | If selected, the Snap's output includes the confidence level for each prediction.
The prediction with the confidence level that is closest to 1 is most likely to be the correct class field.
Valid values: 0 to 1 Default value: Not selected |
| Snap execution | Dropdown list | Select one of the three modes in which the Snap executes.
Available options are:
|
Troubleshooting
None.