


AutoML
automates the process of exploring and tuning machine learning models for a given dataset within the resource limit.
Overview
 Transform-type Snap
Transform-type Snap-
 Does not support Ultra Pipelines
Does not support Ultra Pipelines
AutoML automates the process of exploring and tuning machine learning models for a given dataset within the resource limit.
A machine learning model is a mathematical representation of a real-world process that can be used to predict or solve a specific problem. For example, predict whether the customers are going to churn, predict whether the loan will be fully paid, or, forecast sales. To generate a machine learning model, you must provide training data to a machine learning algorithm to learn from.
Currently, the AutoML Snap supports binary classification, multiclass classification, and regression. For each type of problem, the Snap provides a different set of metrics and reports.
Prerequisites
None.
Known issues
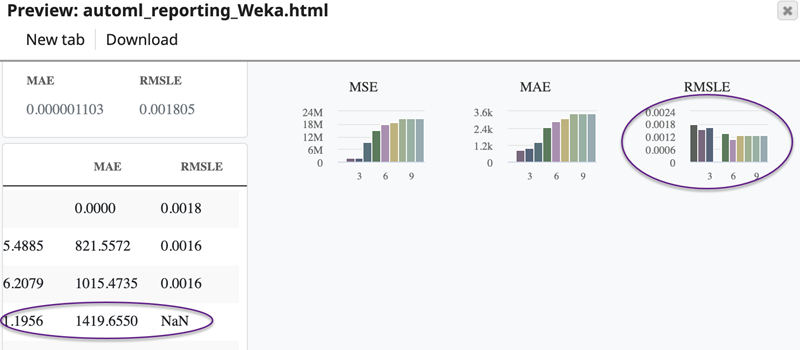
The AutoML generates models with statistical information. If the statistic value of a model for RMSLE is NaN, then the Snap skips that value in charts that are generated in reports.
Snap views
| View | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input #1 | A document stream with classification or regression dataset. | A Snap that generates a classification or regression dataset.
Examples:
|
| Input #2 | A document that contains a model built by an AutoML Snap from a previous execution. | A Snap that offers documents that provide a model built by an AutoML Snap. Example: A combination of File Reader and JSON Parser |
| Output #1 | A serialization of a machine learning model, and metadata that are not human-readable. Additionally, the output includes a human-readable representation of the model if you select the Readable checkbox. | A Snap that formats and saves the model.
Example:
|
| Output #2 | A document that contains the leaderboard. All the models built by this Snap display in the order of ranking along with metrics indicating the performance of the model. | A Snap that accepts documents. Examples: |
| Output #3 | A document that contains an interactive report of up to top 10 models. | A Snap that formats and saves the report.
Example:
|
| Error |
Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter when running the pipeline by choosing one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. |
|
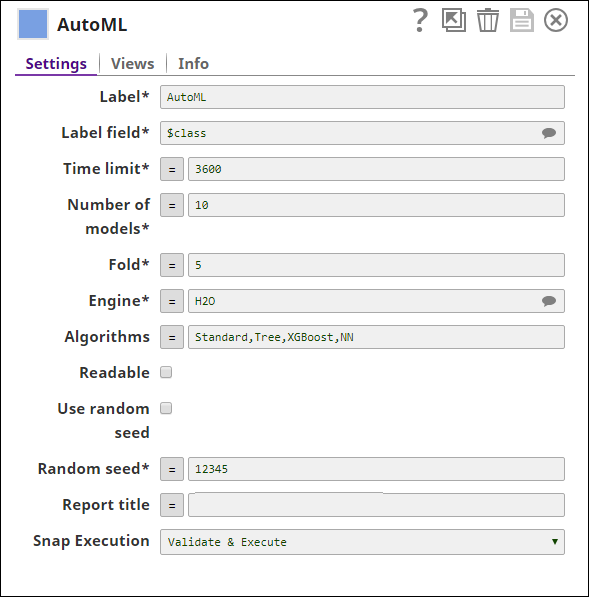
Snap settings
-
Suggestion icon (
 ):
Indicates a list that is dynamically populated based on the configuration.
):
Indicates a list that is dynamically populated based on the configuration.
-
Expression icon (
 ):
Indicates whether the value is an expression (if enabled) or a static value (if disabled).
Learn more about Using Expressions in SnapLogic.
):
Indicates whether the value is an expression (if enabled) or a static value (if disabled).
Learn more about Using Expressions in SnapLogic.
-
Add icon (
 ):
Indicates that you can add fields in the field set.
):
Indicates that you can add fields in the field set.
-
Remove icon (
 ):
Indicates that you can remove fields from the field set.
):
Indicates that you can remove fields from the field set.
| Field / Field set | Type | Description | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Label | String | Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if there are more than one of the same Snap in the pipeline. | |||||||||||||||
| Label field | string | Required. The label/class/target field in the dataset. This is the field you will train the model to predict.
Default value: None Example: |
|||||||||||||||
| Time limit | integer | Required. The maximum number of seconds that the AutoML Snap can be run.
If 0, the Snap builds the number of models specified in the Number of models property, without a time restriction.
Note:
Default value: 3600 |
|||||||||||||||
| Number of models | integer | The number of models that must be included in AutoML.
If 0, the Snap builds as many models as possible within the time specified in the Time limit property.
Note:
Default value: 10 |
|||||||||||||||
| Fold | integer | Required. The number of folds in k-fold cross validation.
Valid values: 2 through 10 Default value: 5 |
|||||||||||||||
| Engine | selection | Required. The engine to be used.
Valid values:
Default value: H2O |
|||||||||||||||
| Algorithms | multiple selection |
Valid values:
Default value: Standard, Tree, XGBoost, NN The AutoML Snap supports the following algorithms:
|
|||||||||||||||
| Readable | checkbox | If selected, the model is displayed in a human-readable format. A $readable field is added to the output.
Default status: Not selected |
|||||||||||||||
| Use random seed | checkbox | If selected, the value of Random seed is applied to the randomizer to get reproducible results.
Default status: Selected |
|||||||||||||||
| Random seed | integer | Required. A number used as the static seed for the randomizer.
Default value: 12345 |
|||||||||||||||
| Report title | string | Title for the report. | |||||||||||||||
| Snap execution | Dropdown list | Select one of the three modes in which the Snap executes.
Available options are:
|
Temporary Files
During execution, data processing on Snaplex nodes occurs principally in-memory as streaming and is unencrypted. When processing larger datasets that exceed the available compute memory, the Snap writes unencrypted pipeline data to local storage to optimize the performance. These temporary files are deleted when the pipeline execution completes. You can configure the temporary data's location in the Global properties table of the Snaplex node properties, which can also help avoid pipeline errors because of the unavailability of space. Learn more about Temporary Folder.
Troubleshooting
None.