

Usecase: Briefing Agent
This use case demonstrates how to create an agent with a specific purpose. For this use case, we are showcasing the Briefing Agent. The Briefing Agent is intended for use by Sales and Marketing teams. While the Agent pipelines are available for you to try, you would have to modify them to fit your environment.
Problem
As a sales team or a marketing team member, research can take a lot of time to put together an informative document for a sales debriefing. Meeting with customers requires careful consideration of participants, roles of the customer team members, and background of the company and its products. This extends to any previous history between your company and the customer.
Solution
It would be ideal to collect the following information before meeting with customers
- Titles of the attendees, to know who are the decision-makers
- Some background information about the company.
- Any previous business history with the customer.
The goal of this agent is to automate this process.
Agent Pipeline Structure
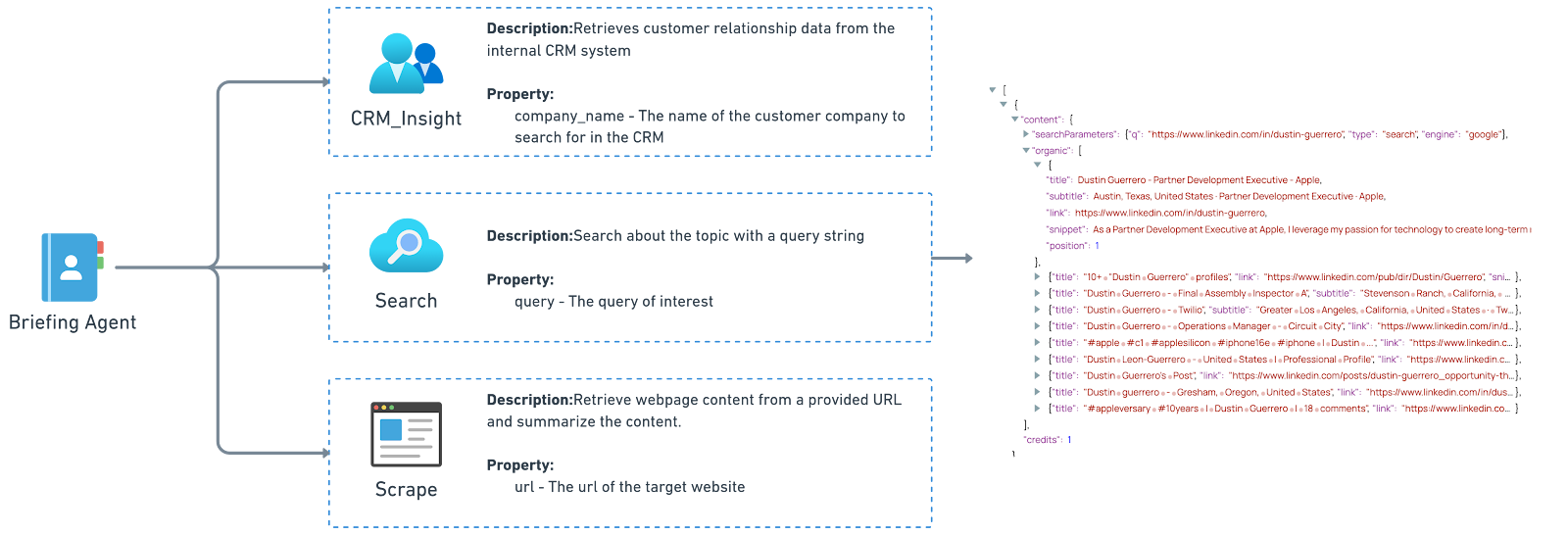
The briefing agent has three tools, which can be used in different combinations based on given tasks.
- CRM Insight tool - Helps retrieve customer relationship data from a CRM system.
- Search tool - Search about a specific topic on Google (attendee names, Company information) using the Google Search API service Serper.
- Scrape tool - Gather information from a website and summarize the content, with a link provided.
System prompt
You are an expert assistant designed to generate comprehensive customer briefings for sales and marketing teams prior to customer visits.
The briefing should include detailed information about the customer company and its team member the sales and marketing team will be meeting with.
This includes but i not limited to their job titles, contact information, professional backgrounds, LinkedIn profiles, and any relavent details.
You will be provided wite names of individuals form a company, and list of company personnel our team will be visiting.
I may also give you specific information I need, such as email addresses or LinkedIn profiles. Please make every effort to find this information for me.
If you are able to find relevant information, present it in bullet points.
If company information cannot be found int he CM system, please use other tools to search it publicly available internet information.
You can use multiple round sof different keywords searches to obtain information.
If the brief search results are insufficient to answer the questions, you can use a tool to obtain the full webpage content.
If you are unable to find sufficient information to generate a useful briefing, respond with: I don't have enough information.Agent pipeline walkthrough
Driver pipeline
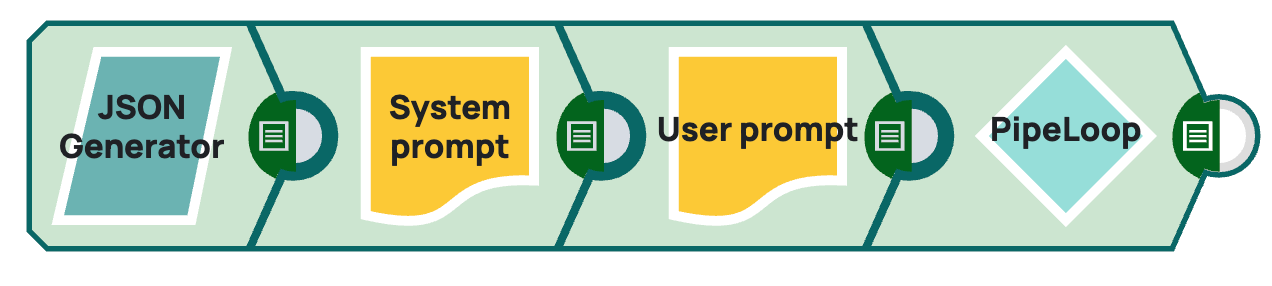
Two prompt generators help build a JSON format to be consumable by the LLM.
- JSON Generator: Generates the JSON document to provide the initial user prompt. It
also helps to have the user prompt in the first JSON Generator Snap when you want to
change the user prompt to a different question. Note: To operationalize this pipeline in conjunction with an interface where users can enter prompts (such as UI application like Streamlit), you can disconnect the JSON Generator Snap and create a Triggered Task from the pipeline, which takes the input of the interface.
- Prompt Generator: Gives system prompt for the downstream LLM.
- Prompt Generator: Creates message array. Select Advanced prompt output and choose USER as the Role.
- PipeLoop: Sends prompt input to Worker Agent pipeline. Here the stop condition is set to 10. Because the downstream LLM is Amazon Bedrock we map the system_ prompt field to the Pipeline Parameter $original.prompt for the Target field. Also, the expression is $stopReason != "tool_use" because in Amazon Bedrock stopReason is the parameter.
Worker pipeline
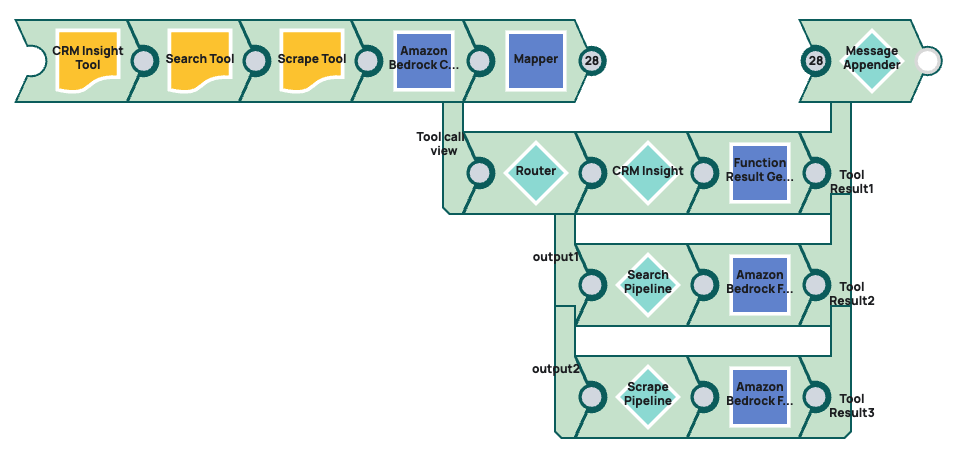
The Worker pipeline is based on routing the prompt input to the three tool pipelines.
- For each of these three tool pipelines the beginning Function Snaps generate the JSON
document specification for the model to call the tool:
- Amazon Bedrock Function Generator - CRM tool
- Amazon Bedrock Function Generator - Search tool
- Amazon Bedrock Function Generator - Scrape tool
- Amazon Bedrock Converse API Tool Calling: Calls the LLM model.
- Mapper Snap: Simplifies the LLM response and formats it as an array for the Message Appender Snap.
- Router Snap: Routes prompt to the three tools:
- Pipeline Execute Snap - CRM Insight: Calls the CRM Insight tool pipeline.
- Function Result Generator: Formats the response returned by the LLM in the CRM insight tool pipeline.
- Pipeline Execute Snap- Search: Calls the CRM Search tool pipeline.
- Function Result Generator: Formats the response returned by the LLM in the CRM Search tool pipeline.
- Pipeline Execute Snap - Scrape: Calls the CRM Search tool pipeline.
- Function Result Generator Snap: Formats the response returned by the LLM in the Scrape tool pipeline.
- Message Appender Snap: Merges the streams from the various tool pipelines into one output.
CRM Insight tool
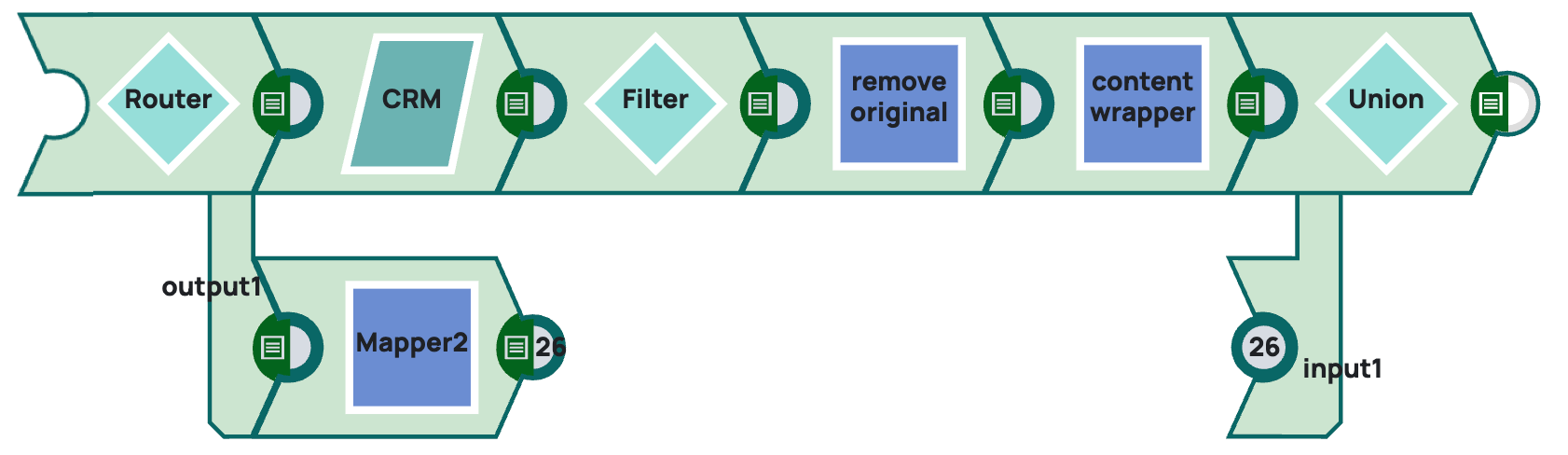
This tool pipeline is designed to query the database for any information pertinent to the sales briefing. This pipeline is not intended as a pattern because the pipeline design greatly depends on the source data system you are querying.
The Router Snap takes the prompt input and splits the stream, sending one output to the CRM database and the other to a Mapper Snap, which defines the response if the information is not found in the CRM.
Sample output:
[
{
"toolUse": {
"toolUseId": "tooluse_eNeM7NzUSpe-JCMMQxElcQ",
"name": "scrape",
"input": {
"url": "https://aws.amazon.com/blogs/machine-learning/unlocking-generative-ai-for-enterprises-how-snaplogic-powers-their-low-code-agent-creator-using-amazon-bedrock/"
}
}
}
]
If the tool is used to search for 3 companies, then those would be routed to the first branch. If the query doesn't turn up results, then the Worker Agent receives that the data pertaining to the company was not found in the database.
Search tool
This tool pipeline is a reusable pattern.
- HTTP Client Snap: Configured to search Google via the Serper tool. We connect via an
API key that's set as a security header. Serper requires the q parameter have value. The
HTTP entity type specified is RAW, and the definition is the following expression:
{"q": $toolUse.input.query} - Mapper Snaps: Maps the incoming
$entityfield to$contentin the Target field for the Agent Worker pipeline.
Web Scrape tool

Used after the search tool. From the list of links and descriptions output by the Search tool, the LLM might select any of the links to scrape the whole webpage and determine if there are any relevant details (in the same way a webcrawler would).
- HTTP Client: This defines the call to the endpoint as a GET call.
- HTML to Markdown Converter: Converts the format of the HTTP output to Markdown format.
- Prompt Generator: Requests the LLM to summarize the Markdown output:
Summarize the content of this webpage, ensuring you capture all information related to individuals, including names, companies, titles, and contact details. Output the summary as a String. {{{content}}} - Amazon Bedrock Converse API Snap: Sends the prompt output to the LLM.